中美AI模型差距消失,应用战开打,如何破局最后的2.7%?

扫描到手机,新闻随时看
扫一扫,用手机看文章
更加方便分享给朋友

出品|搜狐科技
作者|郑松毅
编辑|杨锦
近日,斯坦福HAI重磅发布《2026年AI指数报告》,揭示了中美竞争格局的最新变化。
看完这份长达423页的“AI年度体检报告”,几个关键问题引人思考:中美AI并跑是真赶超还是纸面繁荣?失业潮究竟该AI背锅还是人类反思?科技巨头的狂欢,该由全社会承担环境代价吗?
还有就是,AI狂飙,我们真的准备好了吗?
中美模型差距正在拉平
报告中最吸睛的结论,莫过于“中美顶尖AI模型差距仅2.7%”,宣告全球AI进入“双强并跑”时代,美国2023年的显著领先优势至今已大幅收窄。
Arena榜单数据显示,截止2026年年初,美国顶级AI公司Anthropic最先进的模型在性能表现上,仅仅领先中国最强竞争对手(字节)2.7个百分点。
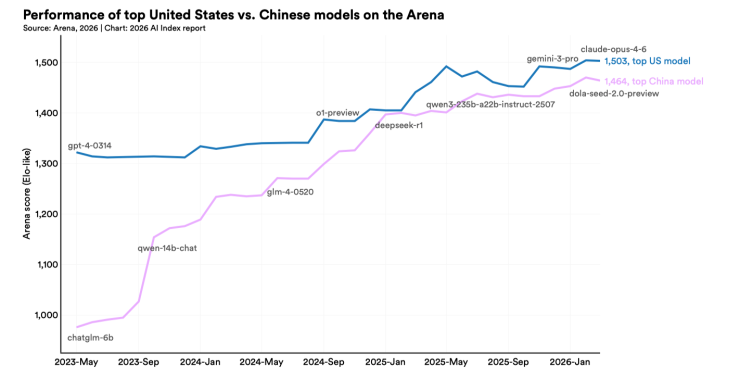
回顾2023年AI热潮掀起初期,OpenAI凭借其旗舰模型1322 分的成绩遥遥领先,而同期谷歌仅为 1117 分。2024年期间,随着谷歌、Anthropic等机构陆续推出更强模型,这一差距持续稳步缩小。
而中国真正开始崭露锋芒,让这场中美博弈出现转折点是在2025年2月。当时DeepSeek发布R1模型短暂追平美国模型,随后双方又进入了新一轮性能迭代期。
从模型产出数量上看,美国在2025年共发布50个有影响力的顶级模型,中国紧随其后发布了30个。
在影响力模型发布数量全球Top 10榜单中,OpenAI、谷歌领跑。中国占了四席,分别是阿里巴巴、DeepSeek、清华大学和字节。

值得关注的是,这些影响力模型超过九成来自产业界,学术机构和政府实验室贡献甚微,前沿模型发布的天平更明显地向产业侧倾斜。
报告出炉后,引发业内两极争论,有人相信“中国已经有实力弯道超车”,也有人直言“当前成绩单只是纸面繁荣”。
支持者表示,中国除了在模型能力侧已无限逼近美国前沿模型,更关键的是,中国AI论文发表量、专利总量全球第一,工业机器人装机量占全球54%,落地应用的广度远超美国。
但也有犀利的反驳观点认为,差距不能只看“模型性能”,更要看“基础设施”。报告明确提及,美国拥有5427个AI数据中心,是中国的10倍以上,算力储备足以支撑更庞大的模型训练;私人AI投资达2859亿美元,是中国的23倍,庞大的资本优势让美国能持续砸钱突破核心技术。
更重要的是,芯片、操作系统等底层技术仍被美国垄断,中国模型看似追平,实则“巧妇难为无米之炊”,一旦遭遇算力封锁,差距可能瞬间拉大。
AI的“天才与白痴”悖论
近年来,AI模型性能加速提升,在图像分类、语言理解、科学问题解答等能力上已超越人类。

智能体任务能力(OSWorld)虽还不及人类,但进化速度最为显著,同样进化显著的还有计算机自主编码能力(SWE-bench Verified)。
报告提到,对于衡量AI极限能力的“人类终极考试(HLE)”而言,截至 2026 年 4 月,表现最优的模型为谷歌 Gemini 3.1 Pro和Anthropic Claude Opus 4.6,答题正确率均超过50%(2025年得分最高的 OpenAI o1 模型,在该测试正确率仅8.8%,年内模型提升显著)。
先别急着恐惧被AI替代,AI能力的不足也显而易见,诸多日常任务无法胜任。
报告通过专门测试时钟读识的ClockBench基准测试,揭示了 AI 在基础视觉推理上的显著不足:顶尖 AI 模型正确读取模拟指针时钟的概率仅为 50.1%,而人类的准确率高达 90.1% 。
整得明白奥赛题,却看不懂钟表,也是怪讽刺的。
报告进一步说明,这种短板并非个例,而是 AI “锯齿状能力前沿”的真实体现——模型在复杂的专业推理、代码生成等领域表现突出,但在需要高精度视觉感知和空间推理的基础日常任务中,有时显得力不从心。
AI的“偏科”问题,至少到今天还未被很好地解决。
22-25岁初级软件开发者就业率暴跌近20%
“AI对人类岗位产生威胁”已经不是新鲜话题,但报告的数据,让这场争议彻底白热化:22-25岁初级软件开发者就业率暴跌近20%,而30岁以上资深开发者就业反而逆势增长。
有人直言“AI是职场内卷的元凶”,也有人反驳“失业的本质是能力和经验不足,没形成技术壁垒,与AI无关”。
有刚毕业的大学生抱怨,“苦学了四年编程,出来发现基础代码开发、修bug的任务AI几分钟就能完成。”企业为了降本增效,果断裁减初级岗位,年轻人的“职业第一台阶”被AI生生截断。
但也有观点认为,AI淘汰的是“不会变通的人”。报告显示,88%的企业采用AI后,虽然裁掉了基础岗,但也新增了AI训练师、增长工程师等新岗位。那些失业的人,大多只依赖基础技能,而不继续提升自己,被淘汰是必然结果。
报告中一个极具讽刺意味的数据,引发了另一场争议:73%的AI专家认为,AI对就业和经济的影响整体正面;但仅23%的普通公众认同这一观点,50个百分点的差距,折射出“行业内部狂欢”与“大众外部焦虑”的严重脱节。
此外,报告还首次披露了AI环境代价,让“技术向善”的口号遭遇拷问:训练Grok 4模型碳排放达72816吨,相当于1.7万辆汽车全年排放量;GPT-4o年用水量超1200万人的饮用水需求,AI已然成为“能耗巨兽”。

这份沉重的环境代价,该由谁来承担?
尽管模型训练成本向来饱受关注,但值得注意的是,当下推理环节的能源消耗占比正在不断上升。模型规模化部署后数月累计的能耗可能超过了模型训练。
报告中提到的基准测试指出,2025年能耗与碳排放排名中,DeepSeek V3.2 Exp和DeepSeek V3.2处理中等长度提示(约1000输入token)的单次能耗(23瓦时)和碳排放(约14克二氧化碳)最高,而Claude 4 Opus等模型能耗(5-6瓦时)和碳排放(1.5-1.6克)较低。表明AI模型推理效率各异,且模型能力与环境代价并非成正比。
有观点认为,科技巨头的AI狂欢不该牺牲环境的沉重代价,他们应该纳“环境税”以保护资源。但也有人反驳道,AI技术的进步,最终会反哺环保——比如用AI优化能源分配、预测极端天气等,长期来看AI对环境的益处会超过代价。
现在来看,当AI竞技卷入下半场,最终的赢家或许不是能力最强的,而是最能适配社会需求的那个。
声明:本文由入驻焦点开放平台的作者撰写,除焦点官方账号外,观点仅代表作者本人,不代表焦点立场。